Here it is: https://forum.zchg.org/watt/
Alternate Link:
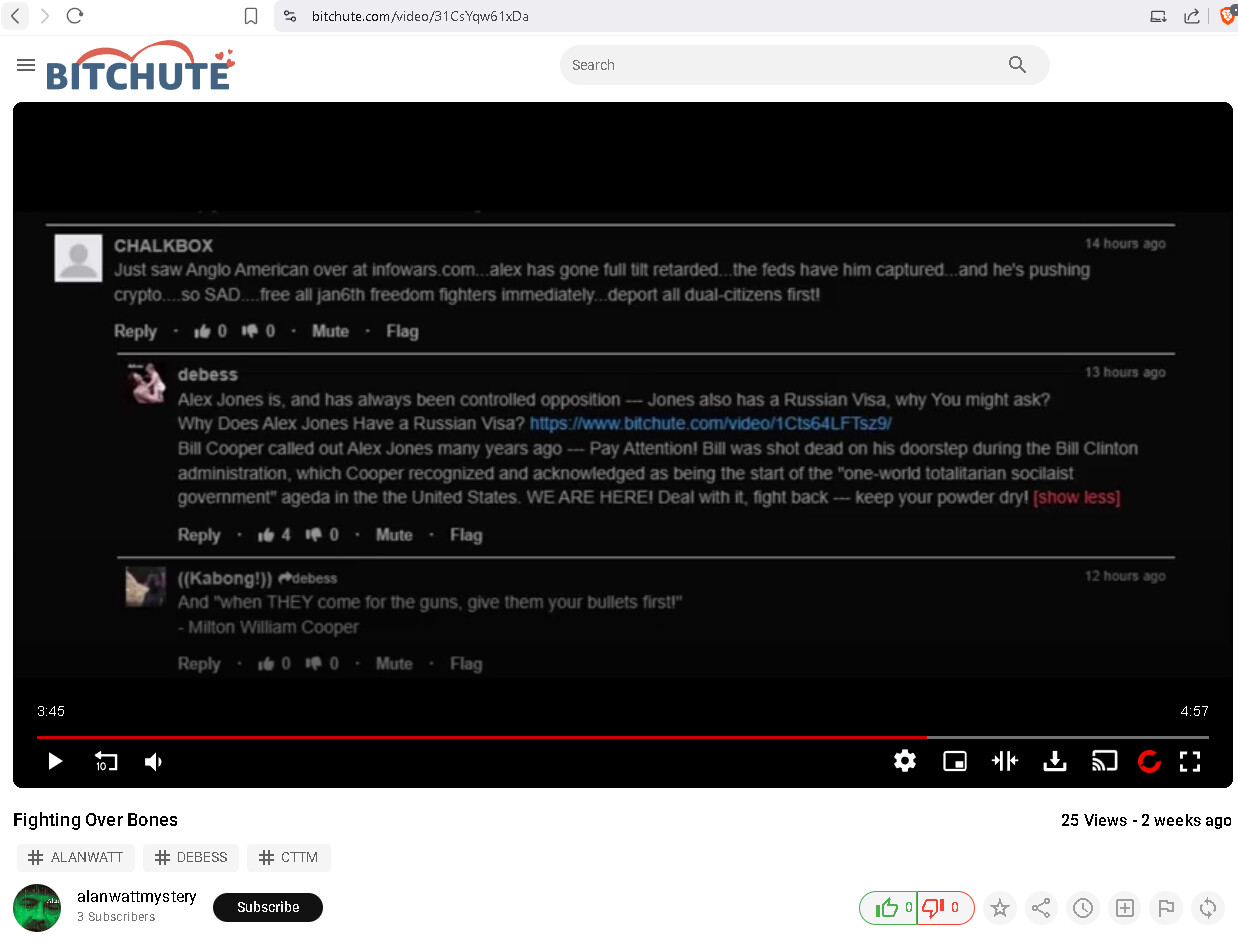
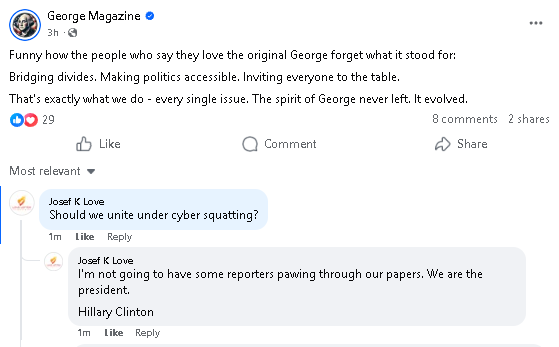
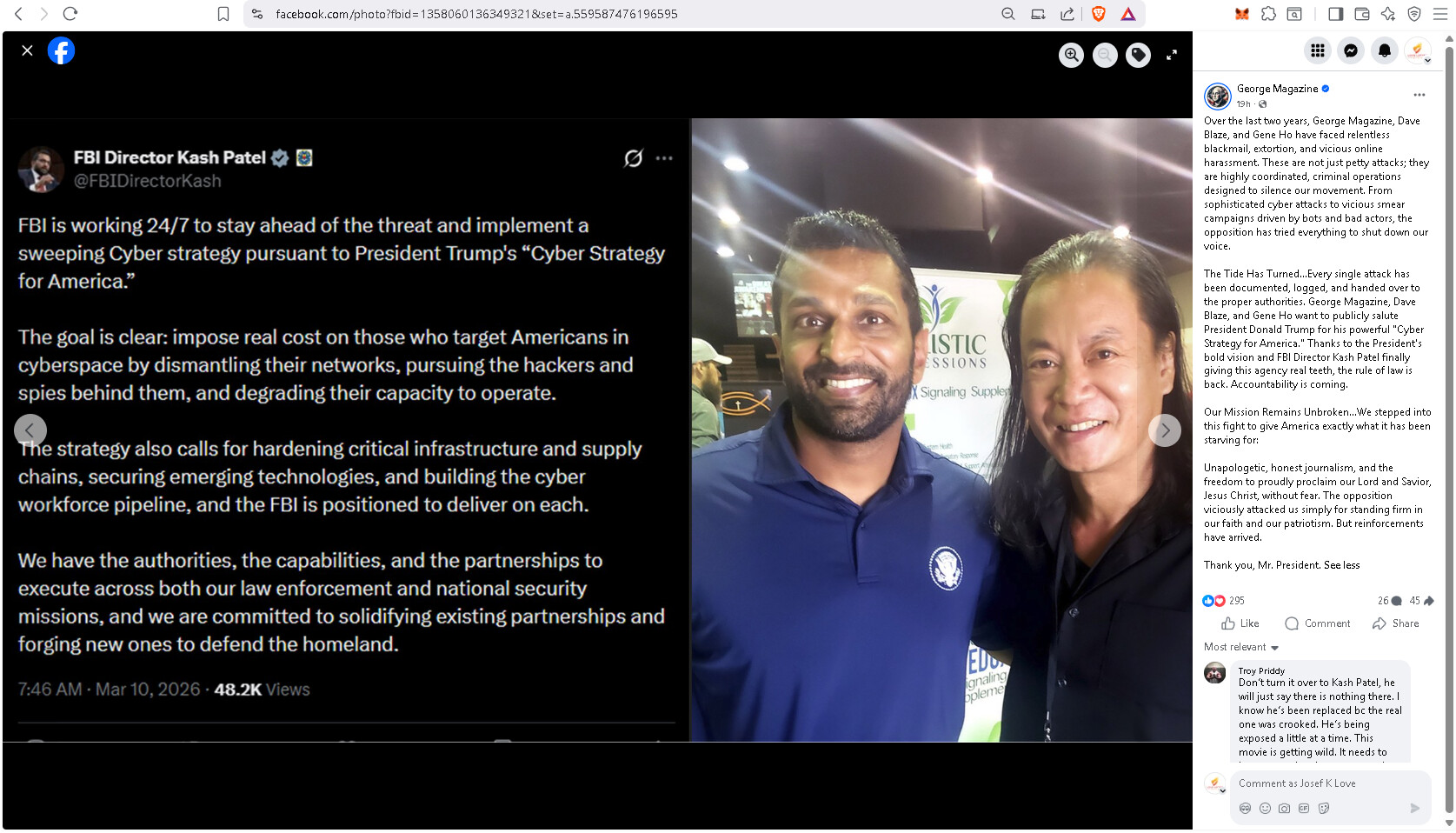
Lawfully. Not an endorsement. What is controlled opposition? What is propping up the straw man to tear down & poison the community well (fallacies)?
A simple tool for archiving:
just run command - python i.py
after installing python and dependencies e.g. python -m pip install requests
i.py
import os
import requests
import xml.etree.ElementTree as ET
from urllib.parse import urlparse
import re
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
import json
# Constants
OUTPUT_DIR = "./media"
LOG_FILE = "./log.txt"
MAX_RETRIES = 3
MAX_THREADS = 4 # Optimal number of simultaneous downloads
# Custom headers to bypass server restrictions
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# Function to sanitize file names by removing or replacing invalid characters
def sanitize_filename(filename):
return re.sub(r'[\\/*?:"<>|]', '_', filename)
def fetch_url_content(url):
"""Fetch content from a URL with custom headers."""
print(f"Fetching XML from: {url}")
response = requests.get(url, headers=HEADERS)
response.raise_for_status()
return response.content
def parse_xml(content):
"""Extract media links and metadata from XML."""
print("Parsing XML content...")
tree = ET.fromstring(content)
items = []
for item in tree.findall('channel/item'):
title = item.findtext('title', '').strip()
enclosure = item.find('enclosure')
if enclosure is not None:
url = enclosure.get('url', '').strip()
if url:
items.append({
'url': url,
'title': title,
})
print(f"Found {len(items)} media files.")
return items
def download_media_item(item, output_dir, retries=0):
"""Download a media file and save it to the specified directory."""
url = item['url']
title = item['title']
sanitized_title = sanitize_filename(title) # Sanitize the title to avoid invalid characters in the filename
# Ensure the file path is safe for Windows
file_name = os.path.join(output_dir, f"{sanitized_title}.mp3" if '.mp3' in url else os.path.basename(url))
print(f"Downloading: {title}\nURL: {url}\nSaving to: {file_name}")
attempt = 0
success = False
# Retry mechanism
while attempt < MAX_RETRIES and not success:
try:
response = requests.get(url, stream=True, headers=HEADERS)
response.raise_for_status()
with open(file_name, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk: # Filter out keep-alive chunks
f.write(chunk)
print(f"Download successful: {file_name}")
success = True
except requests.exceptions.RequestException as e:
attempt += 1
print(f"Error downloading {url}: {e}. Attempt {attempt}/{MAX_RETRIES}")
time.sleep(2 ** attempt) # Exponential backoff
except Exception as e:
print(f"General error: {e}")
break
return success, item
def download_media(media, output_dir):
"""Download media files using parallel threads with progress tracking."""
os.makedirs(output_dir, exist_ok=True)
total_files = len(media)
# Initialize progress bar
with tqdm(total=total_files, desc="Downloading", unit="file") as pbar:
with ThreadPoolExecutor(max_workers=MAX_THREADS) as executor:
futures = {executor.submit(download_media_item, item, output_dir): item for item in media}
for future in as_completed(futures):
item = futures[future]
success, item = future.result()
pbar.update(1) # Update progress bar
# Log result
if not success:
with open(LOG_FILE, 'a') as log:
log.write(f"Failed to download: {item['title']} - {item['url']}\n")
def save_progress(media, filename="download_progress.json"):
"""Save download progress to a file."""
progress = {"downloads": media}
with open(filename, "w") as f:
json.dump(progress, f)
def load_progress(filename="download_progress.json"):
"""Load download progress from a file."""
if os.path.exists(filename):
with open(filename, "r") as f:
return json.load(f).get("downloads", [])
return []
def main(url):
"""Main function to handle XML sources and download media."""
try:
content = fetch_url_content(url)
media = parse_xml(content)
# Create output directory based on the host
parsed_url = urlparse(url)
host_dir = os.path.join(OUTPUT_DIR, parsed_url.netloc)
# Load previous progress (if available) and resume from where we left off
progress = load_progress()
remaining_media = [item for item in media if item not in progress]
if remaining_media:
download_media(remaining_media, host_dir)
save_progress(media) # Save progress after download completion
else:
print("All media files have already been downloaded.")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
url = input("Enter URL to scrape (XML feed): ").strip()
main(url)
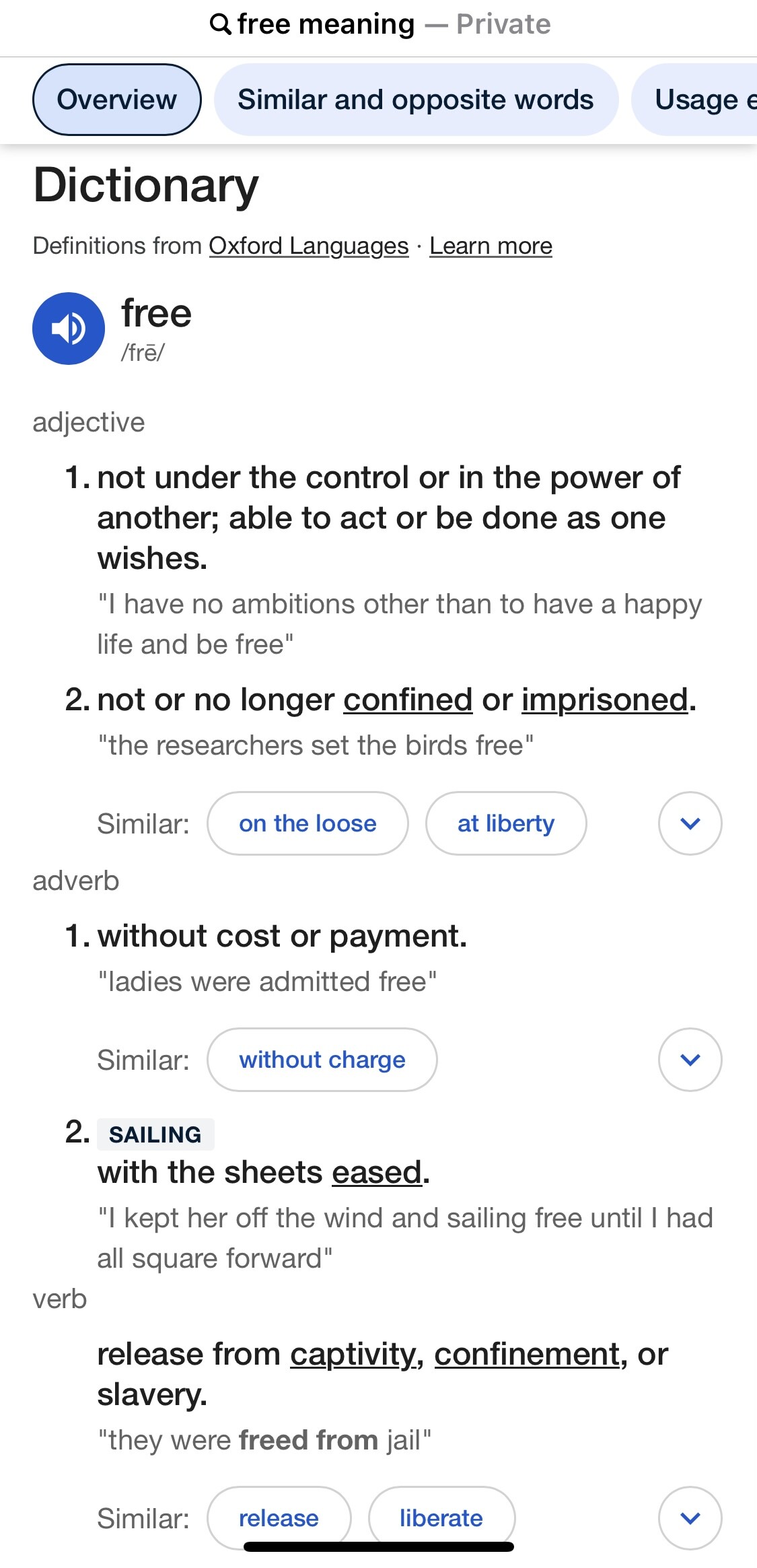
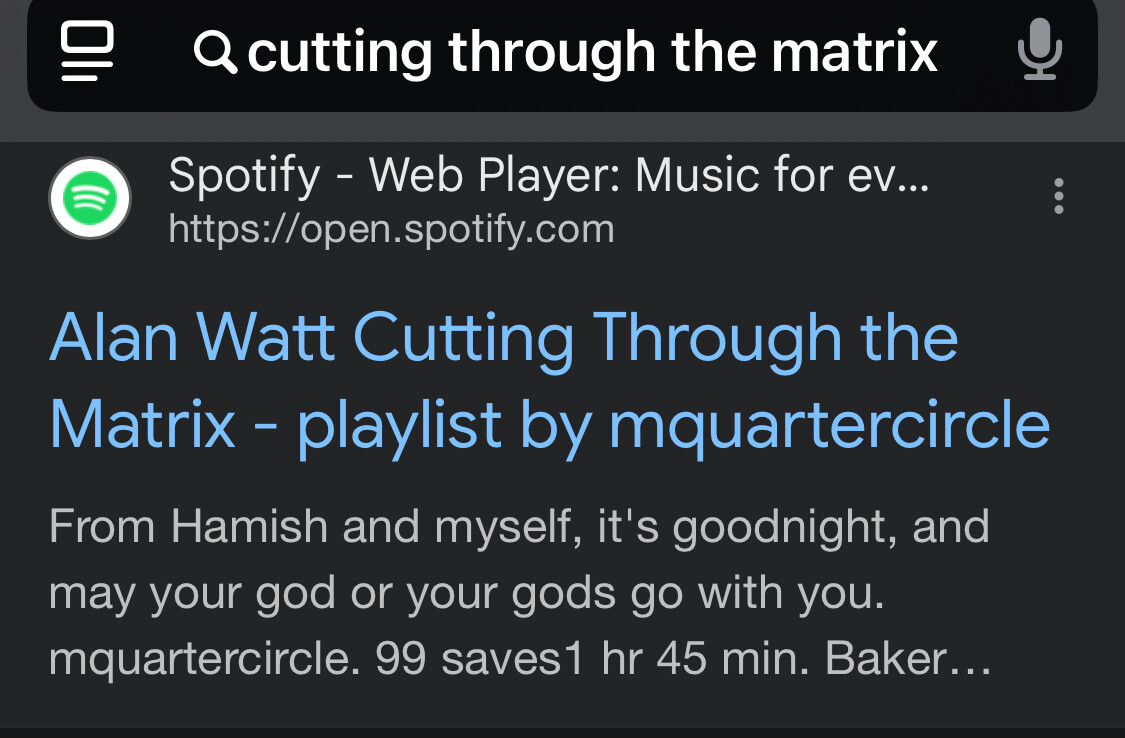
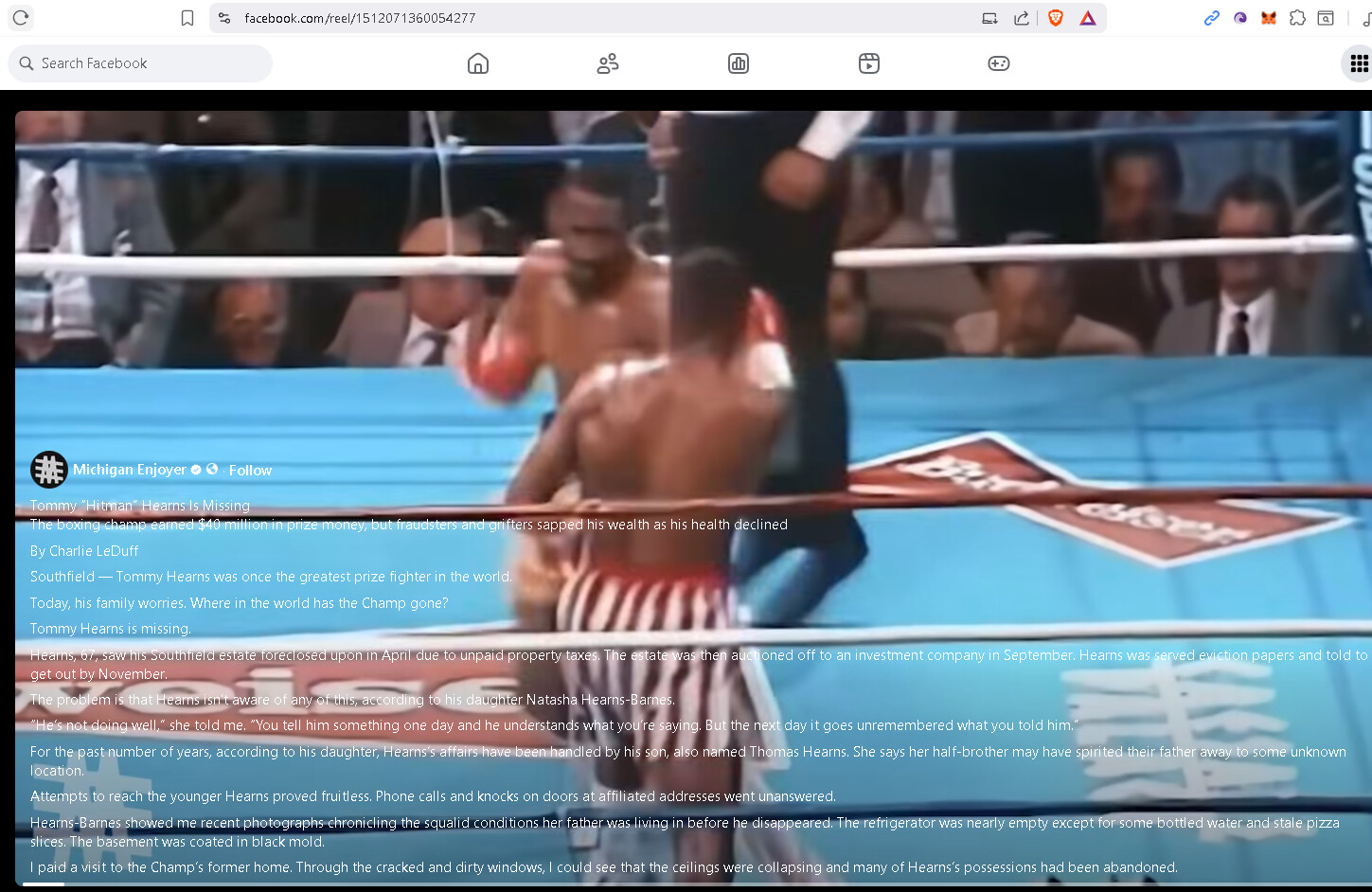
 Wallace vs. Hamish")